Encodage de caractères
L’affichage de caractères… Cela parait être la plus basique des opérations. En fait, pas tant que ça. Qui ne s’est jamais retrouvé face à des pages contenant des “?????????”, “caractères” ou “problème” ?
Je vous propose une “petite” introduction sur les normes d’encodage de caractères.
D’un point de vue technique, l’unité d’information au sein d’un ordinateur est le bit (sa valeur est 0 ou 1). En regroupant ces bits par 8, on obtient un octet (8bits), puis des kilo-octets (ko), méga-octets (Mo), tera-octets (To) etc… Grâce à ces bits (système binaire), on peut obtenir des nombres (système décimale).
Pour représenter et stocker un caractère, il faut donc le transformer en nombre (rôle du jeu de caractères). Ce nombre sera ensuite transformé en bits (rôle de l’encodage de caractères).
Au départ, chaque constructeur avait défini son propre jeu de caractères (correspondance entre les lettres et leur représentation numérique). Cependant, afin que les messages électroniques soient facilement échangeables, il était nécessaire de créer une convention afin que la correspondance entre les caractères et leur représentation numérique soient la même pour tous.
ASCII : le début d’un semblant d’organisation
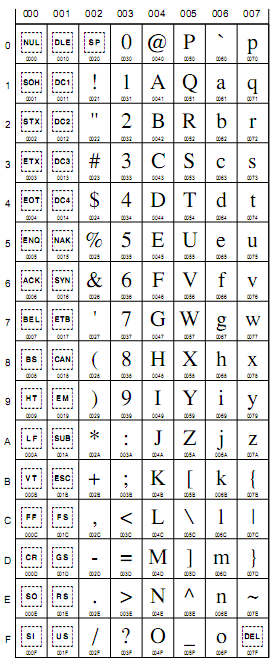
Dans les années 1960, l’un des premiers standards utilisé dans les ordinateurs a été l’ASCII. Cette norme code tous les caractères anglo-saxons (ça aura son importance plus tard) en attribuant à chaque caractère un nombre entre 0 et 127.
Les premières valeurs sont des caractères de contrôle. Ils permettent de faire un retour à la ligne (13), bip sonore (7)… Exemple : le caractère majuscule “A” est représenté par le nombre “65”.
Avec ASCII, l’encodage de caractère est simple : chaque nombre est codé sur 7 bits. La valeur numérique de A est 65. L’encodage sera donc : 010000001.

Gestion des caractères accentués
A ce stade, il n’était pas possible de gérer, ni même d’afficher les caractères accentués des langues autre que l’anglais.
Pour gérer les langues européennes et leurs caractères spéciaux, le groupe de standardisation ISO a créé d’autres normes dérivées de l’ASCII afin de conserver la compatibilité avec celle-ci. L’ASCII étant codé sur 1 octet (8 bits) mais n’utilisant que 7 bits, il a été possible de rajouter les langues européennes sur le dernier bit de l’octet (position 128 à 255). Cependant, il est impossible d’ajouter tous les caractères des langues européennes sur 128 positions. Pour contourner ce problème, il a été créé des normes par langue ou groupe de langues. Ainsi la norme ISO-8859-1 (latin 1) permet de représenter tous les caractères des langues de l’Europe occidentale (anglais, albanais, allemand, catalan, français…). La norme ISO-8859-2, ceux des langues slaves et d’Europe centrale (allemand, croate, hongrois, polonais…).
Cependant, toutes ces normes posent certains problèmes :
- Comment représenter des langues basées sur des symboles ? le chinois possède des milliers de caractères. Le codage sur 1 octet est impossible.
- Comment fonctionnera l’échange d’information entre une application codée en ISO-8859-1 et une autre codée en ISO-8859-2 ?
- Si l’application est utilisée en Pologne (ISO-8859-2), comment s’afficheront les caractères accentués français à l’écran ?
- Comment créer puis partager un document mélangeant du texte français, chinois et hongrois ?
Dans un monde où la mondialisation et l’échange d’information sont omniprésents, il était nécessaire de remettre à plat le système de jeux de caractères afin qu’un nombre représente un seul caractère quelque soit la plate-forme, le programme ou le langage.
UNICODE : une norme pour les gouverner toutes
Cette norme, développée dans les années 1990, permet le support de la majorité des caractères utilisés dans les langues du monde entier. UNICODE définit comment interpréter les caractères, mais ne définit pas comment représenter ces caractères. Cette tâche est gérée par le programme notamment par la police de caractère utilisée.
La norme fait donc la différence entre les caractères et leur glyphe respectif (représentation graphique d’un caractère).
Exemple :
Les lettres majuscule ve (cyrillique), beta (grecque) et b (latin) ont le même glyphe. Cependant, dans UNICODE, ce sont des caractères différents avec des codes différents. En effet, imaginons que le même code ait été utilisé pour ces 3 caractères et que l’on souhaite passer ce caractère en minuscule : comment savoir s’il faut afficher в , β ou b ?
Au niveau du jeu de caractère, UNICODE associe un nombre à un caractère. La table de caractères est accessible sur le site officiel UNICODE. Ce nombre pouvant être grand, UNICODE le stocke en hexadécimal :
Exemples : la lettre A majuscule est définie par le code “U+0041” (en système décimal, 0041 = 65). En UNICODE, le mot “HELLO” sera donc représenté ainsi : U+0048 U+0065 U+006C U+006C U+006F Ici, il s’agit simplement de la représentation numérique des caractères. Comment sont-ils alors représentés en mémoire ?
Encodage des caractères avec UNICODE
Les données peuvent être transmises sur 8, 16 ou 32 bits respectivement appelés : UTF8, UTF16, UTF32. Le choix entre ces différentes formes d’encodage dépend de ce que l’on souhaite faire de ces caractères (traitement, stockage en mémoire…).
- UTF-32 : les caractères sont codés sur 32 bits (soit 4 octets, 2^32 caractères).
- UTF-16 : les caractères sont codés sur 16 bits minimum (soit 2 octets, 2^16 caractères). Pour les caractères dont la représentation numérique est supérieure à 65 535. Ils sont alors codés sur 4 octets.
- UTF-8 : les caractères sont codés de 1 à 4 octets suivant le caractère. Les caractères définit dans ASCII sont codés sur 1 octet, les caractères Européens et du Proche-Orient sur 2 octets et les “caractères” asiatiques sur 3 ou 4 octets. C’est une version optimisée des 2 premiers. En effet, un texte ne contenant que des caractères ASCII sera codé sur moins d’octets en UTF-8 (exemple : la lettre “A” sera codé sur 1 octet en UTF-8 alors qu’elle le serait sur 4 octets en UTF-32). L’intérêt principal est un gain en terme de stockage mémoire et, par conséquent, de vitesse de transmission (imaginez les différences de stockage pour un document contenant 100 000 caractères).
On pourrait se dire qu’il suffit que tout le monde utilise UTF-32 pour que tous les caractères soient affichables. Cela fonctionnerait effectivement, mais un document demanderait 4 fois plus d’espace disque et de mémoire s’il était encodé en UTF-32 plutôt qu’en ASCII.
Note : en UNICODE, des octets ont été ajoutés pour signaler comment les octets sont organisés au sein de la chaine de caractères : le BOM. Toutes les réponses sur le BOM se trouve ici.
Sauf cas particuliers, la forme d’encodage conseillée pour web est l’UTF-8 (sans BOM). Elle a l’avantage de coder les premiers caractères latins (les plus utilisés dans un texte) comme l’ASCII sur 1 octet. Ainsi la taille du document restera raisonnable.
Les octets en action
Prenons une chaine de caractères : HELLO é 日本
Créons un fichier texte encodé avec ASCII, puis UNICODE (UTF-8 sans et avec BOM), (UTF-16 BE) et (UTF-16LE). Le fichier contient une chaine de 10 caractères : 7 caractères font partie de la table ASCII et 3 n’en font pas partie.
Fichier ISO-8859-1
En se reportant à la table ASCII, on obtient :
| Caractère | Décimal | Hexadécimal | Commentaire |
|---|---|---|---|
| H | 72 | 48 | |
| E | 69 | 45 | |
| L | 76 | 4C | |
| L | 76 | 4C | |
| O | 79 | 4F | |
| [espace] | 32 | 20 | |
| é | 233 | E9 | définit dans la norme ISO-8859-1 |
| [espace] | 32 | 20 | |
| 日 | ? | ? | non définie dans ISO-8859-1 |
| 本 | ? | ? | non définie dans ISO-8859-1 |
Chaque caractère est codé sur 1 octet. Les 2 caractères japonais n’existent pas dans ISO-8859-1. En revanche, en utilisant ISO-2022-JP, nous aurions pu les encoder correctement. La taille totale du fichier est de 10 octets.
En utilisant un éditeur de code hexadécimal, on peut retrouver ces valeurs :

Fichier UTF-8 (sans BOM)
| Caractère | Code Unicode | Code hexadécimal | Commentaire |
|---|---|---|---|
| H | U+0048 | 48 | |
| E | U+0045 | 45 | |
| L | U+004C | 4C | |
| L | U+004C | 4C | |
| O | U+004F | 4F | |
| [espace] | U+0020 | 20 | |
| é | U+00E9 | E9 | |
| [espace] | U+0020 | 20 | |
| 日 | U+65E5 | E6 97 A5 | Unicode Han Character ‘sun; day; daytime’ |
| 本 | U+672C | E6 9C AC | Unicode Han Character ‘root, origin, source; basis’ |
Comme définit précédemment, tous les caractères présents dans ASCII sont codés sur 1 octet. Pour la lettre “é”, UNICODE utilise 2 octets (C3 E9) et 3 octets pour chaque caractère japonais. On obtient donc 7 x 1 octet + 2 octets + 2 x 3 octets = 15 octets.

On aperçoit également sur la droite le texte affiché en utilisant l’encodage ISO-8859-1.
### Fichier UTF-8(avec BOM)
| Caractère | Code Unicode | Code hexadécimal | Commentaire |
|---|---|---|---|
| H | U+0048 | 48 | |
| E | U+0045 | 45 | |
| L | U+004C | 4C | |
| L | U+004C | 4C | |
| O | U+004F | 4F | |
| [espace] | U+0020 | 20 | |
| é | U+00E9 | E9 | |
| [espace] | U+0020 | 20 | |
| 日 | U+65E5 | E6 97 A5 | Unicode Han Character ‘sun; day; daytime’ |
| 本 | U+672C | E6 9C AC | Unicode Han Character ‘root, origin, source; basis’ |
L’encodage est équivalent avec ou sans BOM. Cependant, la taille du fichier est de 18 octets. En effet, en début de fichier, on a 3 octets : EF BB BF. Ces octets correspondent au BOM qui donne l’organisation mémoire des octets.

### Fichier UTF-16 BE
| Caractère | Code Unicode | Code hexadécimal | Commentaire |
|---|---|---|---|
| H | U+0048 | 00 48 | |
| E | U+0045 | 00 45 | |
| L | U+004C | 00 4C | |
| L | U+004C | 00 4C | |
| O | U+004F | 00 4F | |
| [espace] | U+0020 | 00 20 | |
| é | U+00E9 | 00 E9 | |
| [espace] | U+0020 | 00 20 | |
| 日 | U+65E5 | 65 E5 | Unicode Han Character ‘sun; day; daytime’ |
| 本 | U+672C | 67 2C | Unicode Han Character ‘root, origin, source; basis’ |
Comme définit précédemment, tous les caractères sont codés sur 2 octets (caractères ASCII compris). Pour la lettre “é”, UNICODE utilise 2 octets (C3 E9) et 3 octets pour chaque caractère japonais. On obtient donc 10 x 2 octets = 20 octets.
Cependant, la taille du fichier est de 22 octets toujours à cause du BOM qui prend la valeur “FE FF” en UTF-16BE.

Fichier UTF-16 LE
| Caractère | Code Unicode | Code hexadécimal | Commentaire |
|---|---|---|---|
| H | U+0048 | 48 00 | |
| E | U+0045 | 45 00 | |
| L | U+004C | 4C 00 | |
| L | U+004C | 4C 00 | |
| O | U+004F | 4F 00 | |
| [espace] | U+0020 | 20 00 | |
| é | U+00E9 | E9 00 | |
| [espace] | U+0020 | 20 00 | |
| 日 | U+65E5 | E5 65 | Unicode Han Character ‘sun; day; daytime’ |
| 本 | U+672C | 2C 67 | Unicode Han Character ‘root, origin, source; basis’ |
Le seul changement entre UTF-16 BE et UTF-16 LE est la différence d’organisation des octets. Le BOM prend, cette-fois-ci, la valeur “FF FE”.

Récapitulatif
| Encodage | Taille du fichier (en octet) | Commentaire |
| ISO-8859-1 | 10 | Poids en octet le plus faible. N’encode pas tous les caractères |
| UTF-8 (sans BOM) | 15 | Encode tous les caractères sur 1 octet minimum |
| UTF-8 (avec BOM) | 18 | Encode tous les caractères. Ajoute 3 octets correspondant au BOM |
| UTF-16 (BE) | 20 | Encode tous les caractères sur 2 octets au minimum |
| UTF-16 (LE) | 20 | Encode tous les caractères sur 2 octets au minimum |
Affichage des caractères
Après avoir parlé de l’encodage des caractères, il reste une étape : l’affichage. L’affichage des caractères est fait par l’intermédiaire des polices de caractères (fonts). Celles-ci doivent posséder le glyphe correspondant au caractère encodé pour l’afficher correctement.
Voici une liste de différentes polices de caractères UNICODE disponibles gratuitement.
Comment savoir si vos polices de caractères affichent certains caractères UNICODE ? Il suffit d’installer un logiciel qui va analyser votre fichier et lister tous les glyphes disponibles.
Sous Linux, Windows et Mac, vous pouvez utiliser FontMatrix.
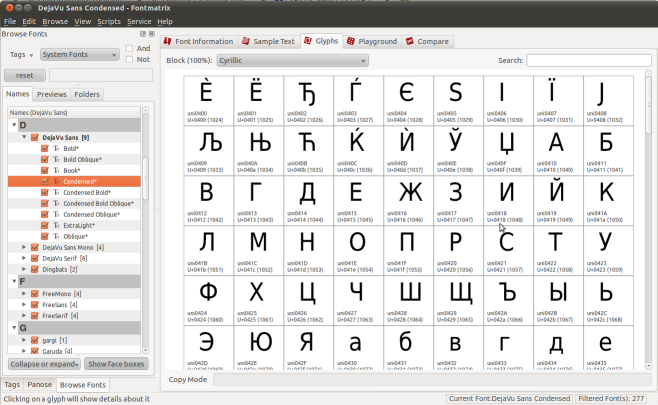
Dans cette exemple, on peut voir que la police de caractère “DejaVu Sans” possèdent les glyphes correspondants au caractères cyrilliques définis par UNICODE.
Il existe des logiciels permettant d’ajouter, modifier ou supprimer des glyphes au sein d’une police de caractères. FontForge est disponible sous Linux, Windows et est gratuit.
Ressources
- Site officiel UNICODE
- Wikipedia (ASCII)
- Wikipedia (UNICODE)
- Base de données eki.ee : diverses opérations sur les normes ISO, recherche de caractères UNICODE
- Fileformat.info : recherche de caractères UNICODE